基本概念 数据结构: 相互之间存在一种或者多种特定关系的数据元素的集合。在逻辑上可以分为线性结构,散列结构,树形结构,图形结构 等等。
算法: 求解具体问题的步骤描述,代码上表现的是解决特定问题的一组有限的指令序列。
算法复杂度 :时间和空间复杂度 ,衡量算法效率,算法在执行过程中,随着数据规模n的增长,算法执行所花费的时间和空间的增长速度 。
常见的时间复杂度 :
大O计法
应用实例
O(1)
数组随机访问,哈希表
O(logn)
二分搜素,二叉堆调整,AVL,红黑树查找
O(n)
线性搜索
O(nlogn)
堆排序,快速排序,归并排序
O(n^2)
冒泡排序,选择排序,插入排序
O(2^n)
子集树
O(n!)
排列树
常见算法的时间复杂度关系:O(1)<O(logn)<O(n)<O(nlogn)<O(n^2)<O(2^n)<O(n!)<O(n^n)
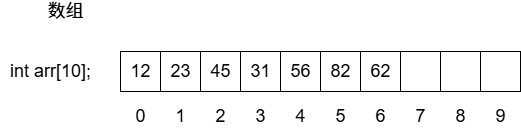
线性表 数组
特点:内存是连续的。
优点:
下标访问(随机访问)时间复杂度是O(1)
末尾位置增加/删除元素时间复杂度是O(1)
访问元素前后相邻位置的元素非常方便。
缺点:
非末尾位置增加/删除元素需要进行大量的数据移动,时间复杂度O(n)
搜索的时间复杂度:当是无序数组时,线性搜索O(n)。当是有序数组时,二分搜索O(logn)
数组扩容消耗比较大(这里需要解释),看下列扩容代码
数组本身及基本功能实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 #include <iostream> #include <time.h> class Array { public : Array (int size = 10 ) :mCur (0 ), mCap (size) { mpArr = new int [mCap](); } ~Array () { delete [] mpArr; mpArr = nullptr ; } void push_back (int val) { if (mCur == mCap) { expand (2 * mCap); } mpArr[mCur++] = val; } void pop_back () { if (mCur == 0 ) { return ; } mCur--; } void insert (int pos, int val) { if (pos<0 || pos>mCap) { return ; } if (mCur == mCap) { expand (2 * mCap); } for (int i = mCur - 1 ;i >= pos;i--) { mpArr[i + 1 ] = mpArr[i]; } mpArr[pos] = val; mCur++; } void erase (int pos) { if (pos<0 || pos>=mCur) { return ; } for (int i = pos + 1 ;i < mCur;i++) { mpArr[i - 1 ] = mpArr[i]; } mCur--; } int find (int val) { for (int i = 0 ;i < mCur;i++) { if (mpArr[i] == val) { return i; } } return -1 ; } void show () const { for (int i = 0 ;i < mCur;i++) { std::cout << mpArr[i] << " " ; } std::cout << std::endl; } private : int * mpArr; int mCap; int mCur; void expand (int size) { int * p = new int [size]; memcpy (p, mpArr, sizeof (int ) * mCap); delete []mpArr; mpArr = p; mCap = size; } }; int main () Array arr; srand (time (0 )); for (int i = 0 ;i < 10 ;i++) { arr.push_back (rand () % 100 ); } arr.show (); arr.pop_back (); arr.show (); arr.insert (0 , 100 ); arr.show (); arr.insert (10 , 200 ); arr.show (); int pos = arr.find (100 ); if (pos != -1 ) { arr.erase (pos); } arr.show (); }
数组应用 1.逆序字符串(使用双指针)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void Reverse (char arr[], int size) char * p = arr; char * q = arr + size - 1 ; while (p < q) { char ch = *p; *p = *q; *q = ch; p++; q--; } } int main () char arr[] = "hello world" ; Reverse (arr, strlen (arr)); std::cout << arr << std::endl; }
2.整型数组,把偶数调整到数组的左边,把奇数调整到数组的右边
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 void AdjustArray (int arr[], int size) int * p = arr; int * q = arr + size - 1 ; while (p < q) { while (p < q) { if ((*p & 0x1 ) == 1 ) { break ; } p++; } while (p < q) { if ((*q & 0x1 ) == 0 ) { break ; } q--; } if (p < q) { int tmp = *p; *p = *q; *q = tmp; p++; q--; } } } int main () int arr[10 ] = { 0 }; srand (time (0 )); for (int i = 0 ;i < 10 ;i++) { arr[i] = rand () % 100 ; } for (int v : arr) { std::cout << v << " " ; } std::cout << std::endl; AdjustArray (arr,10 ); for (int v : arr) { std::cout << v << " " ; } std::cout << std::endl; }
3.移除元素(leetcode 27)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution {public : int removeElement (vector<int >& nums, int val) int i=0 ,j=nums.size ()-1 ; while (i<=j) { if (nums[i]!=val) { i++; continue ; } if (nums[j]==val) { j--; continue ; } nums[i++]=nums[j--]; } return i; } };
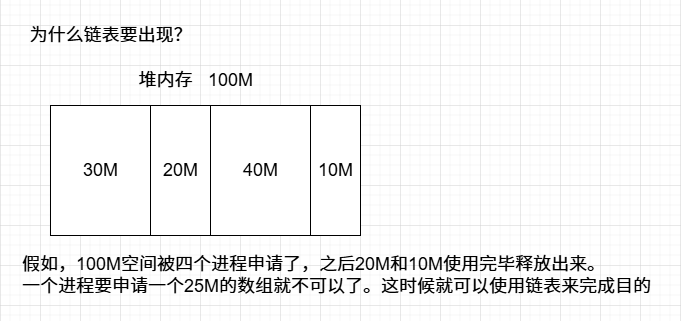
链表
特点:每一个节点都是在堆内存上独立出来的,节点内存不连续
优点:
内存利用率高,不需要大块连续内存
插入和删除节点不需要移动其他节点,时间复杂度O(1)
不需要专门进行扩容操作
缺点:
内存占用量大,每一个节点多出存放地址的空间
节点内存不连续,无法进行内存随机访问
链表搜索效率不高,只能从头节点开始逐节点遍历。
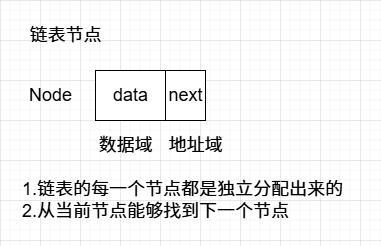
链表节点:
1 2 3 4 5 struct Node { int data; Node *next; }
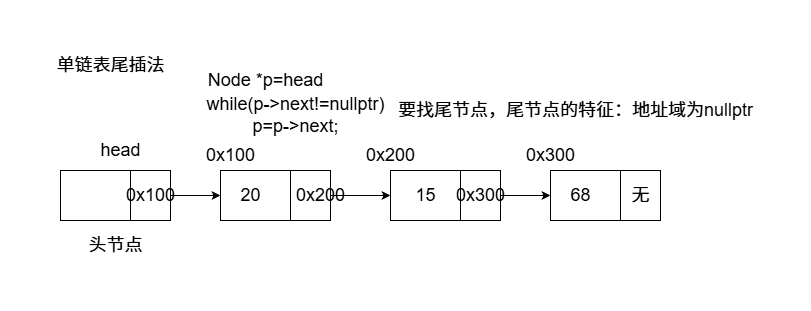
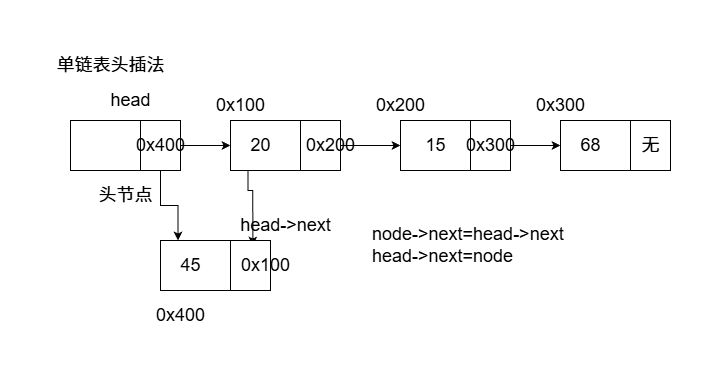
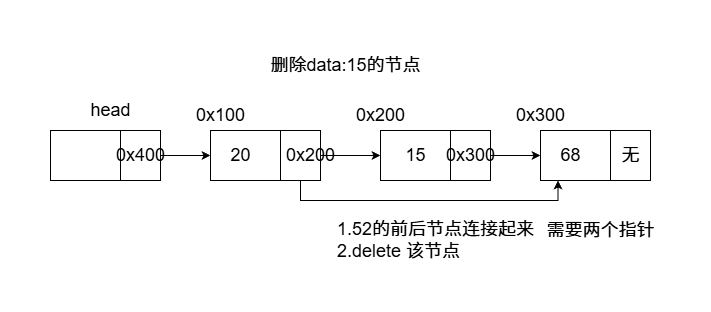
单链表 每一个节点只能找到下一个节点,无法回退到上一个节点,末尾节点的指针域是nullptr
单链表接口实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 #include <iostream> #include <stdlib.h> #include <time.h> using namespace std;struct Node { Node (int data = 0 ) :data_ (data), next_ (nullptr ) {} int data_; Node* next_; }; class Clink { public : Clink () { head_ = new Node (); } ~Clink () { Node* p = head_; while (p != nullptr ) { head_ = head_->next_; delete p; p = head_; } head_ = nullptr ; } public : void insertTail (int val) { Node* p = head_; while (p->next_ != nullptr ) { p = p->next_; } Node* node = new Node (val); p->next_ = node; } void insertHead (int val) { Node* node = new Node (val); node->next_ = head_->next_; head_->next_ = node; } void Remove (int val) { Node* q = head_; Node* p = head_->next_; while (p != nullptr ) { if (p->data_ == val) { q->next_ = p->next_; delete p; return ; } else { q = p; p = p->next_; } } } void RemoveAll (int val) { Node* q = head_; Node* p = head_->next_; while (p != nullptr ) { if (p->data_ == val) { q->next_ = p->next_; delete p; p = q->next_; } else { q = p; p = p->next_; } } } bool Find (int val) { Node* p = head_->next_; while (p != nullptr ) { if (p->data_ == val) { return true ; } else { p = p->next_; } } return false ; } void Show () { Node* p = head_->next_; while (p != nullptr ) { std::cout << p->data_ << " " ; p = p->next_; } } private : Node* head_; }; int main () Clink link; srand (time (0 )); for (int i = 0 ;i < 10 ;i++) { int val = rand () % 100 ; link.insertHead (val); std::cout << val << " " ; } std::cout << std::endl; link.Show (); std::cout << std::endl; link.insertHead (23 ); link.insertTail (23 ); link.Show (); std::cout << std::endl; link.RemoveAll (23 ); link.Show (); }
单链表应用 1.单链表逆序(leetcode206)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class Solution {public : ListNode* reverseList (ListNode* head) { if (head==nullptr ) return nullptr ; ListNode prehead; prehead.next=head; ListNode *tmp=nullptr ; ListNode *cur=prehead.next; prehead.next=nullptr ; while (cur!=nullptr ) { tmp=cur->next; cur->next=prehead.next; prehead.next=cur; cur=tmp; } return prehead.next; } };
2.单链表求倒数第K个节点(leetcode 面试题02.02)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Solution {public : int kthToLast (ListNode* head, int k) ListNode *pre=head; ListNode *p=head; for (int i=0 ;i<k;i++) { p=p->next; } while (p!=nullptr ) { p=p->next; pre=pre->next; } return pre->val; } };
3.合并两个有序单链表(leetcode 21)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 class Solution {public : ListNode* mergeTwoLists (ListNode* list1, ListNode* list2) { ListNode prehead; prehead.next=list1; ListNode *last=&prehead; ListNode *p=list1; ListNode *q=list2; while (p!=nullptr && q!=nullptr ) { if (q->val<=p->val) { last->next=q; q=q->next; last=last->next; } else { last->next=p; p=p->next; last=last->next; } } if (p!=nullptr ) { last->next=p; } if (q!=nullptr ) { last->next=q; } return prehead.next; } };
4.单链表判断是否有环?求环的入口节点(leetcode 142)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Solution {public : ListNode *detectCycle (ListNode *head) { ListNode *fast=head; ListNode *slow=head; if (head==nullptr ||head->next==nullptr ) { return nullptr ; } while (fast!=nullptr &&fast->next!=nullptr ) { fast=fast->next->next; slow=slow->next; if (fast==slow) { ListNode *huan=head; while (huan!=fast) { huan=huan->next; fast=fast->next; } return huan; } } return nullptr ; } };
5.判断两个单链表是否相交(leetcode 160)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 class Solution {public : ListNode *getIntersectionNode (ListNode *headA, ListNode *headB) { ListNode *pa=headA; ListNode *pb=headB; int ia=0 ; int ib=0 ; while (pa!=nullptr ) { ia++; pa=pa->next; } while (pb!=nullptr ) { ib++; pb=pb->next; } pa=headA; pb=headB; if (ia>ib) { for (int i=ia-ib;i>0 ;i--) pa=pa->next; while (pa!=pb) { pa=pa->next; pb=pb->next; } if (pa==nullptr ) { return nullptr ; } return pa; }else { for (int i=ib-ia;i>0 ;i--) pb=pb->next; while (pa!=pb) { pa=pa->next; pb=pb->next; } if (pa==nullptr ) { return nullptr ; } return pa; } } };
6.删除链表倒数第N个节点(leetcode 19)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class Solution {public : ListNode* removeNthFromEnd (ListNode* head, int n) { if (n<=0 ) return nullptr ; ListNode *p=head; ListNode *q=head; for (int i=0 ;i<n;i++) { q=q->next; } if (q==nullptr ) { head=head->next; return head; } while (q->next!=nullptr ) { p=p->next; q=q->next; } p->next=p->next->next; return head; } };
7.旋转链表(leetcode 61)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class Solution {public : ListNode* rotateRight (ListNode* head, int k) { if (head==nullptr ) { return nullptr ; } ListNode *p=head; int i=0 ; while (p!=nullptr ) { i++; p=p->next; } p=head; ListNode *q=head; for (int j=0 ;j<(k%i);j++) { q=q->next; } while (q->next!=nullptr ) { p=p->next; q=q->next; } q->next=head; head=p->next; p->next=nullptr ; return head; } };
单向循环链表 特点
每一个节点除了数据域,还有一个next指针域指向下一个节点。
末尾节点的指针域指向头节点。
接口实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 #include <iostream> #include <stdlib.h> #include <time.h> class CircleLink { public : CircleLink () { head_ = new Node (); tail_ = head_; head_->next_ = head_; } ~CircleLink () { Node* p = head_->next_; while (p != head_) { head_->next_ = p->next_; delete p; p = head_->next_; } delete head_; } void InsertTail (int val) { Node* p = new Node (val); p->next_ = head_; tail_->next_ = p; tail_ = p; } void InsertHead (int val) { Node* node = new Node (val); node->next_ = head_->next_; head_->next_ = node; if (node->next_ == head_) { tail_ = node; } } void Remove (int val) { Node* q = head_; Node* p = head_->next_; while (p!= head_) { if (p->data_ == val) { q->next_ = p->next_; delete p; if (q->next_ == head_) { tail_ = q; } return ; } else { q = p; p = p->next_; } } } bool Find (int val) const { Node* p = head_->next_; while (p != head_) { if (p->data_ == val) { return true ; }else { p = p->next_; } } return false ; } void Show () const { Node* p = head_->next_; while (p != head_) { std::cout << p->data_ << " " ; p = p->next_; } std::cout << std::endl; } private : struct Node { Node (int data = 0 ) :data_ (data), next_ (nullptr ) {} int data_; Node* next_; }; Node* head_; Node* tail_; }; int main () CircleLink clink; srand (time (NULL )); clink.InsertHead (100 ); for (int i = 0 ;i < 10 ;i++) { clink.InsertTail (rand () % 100 ); } clink.Show (); clink.InsertTail (200 ); clink.Show (); clink.Remove (200 ); clink.Show (); }
约瑟夫环问题
已知n个人(以编号1,2,3…n分别表示)围坐在一张圆桌,从编号为k的人开始报数,数到m的那个人出列,他的下一个人又从1开始报数,数到m的那个人又出列,依此规律重复下去,直到全部出列,求输出人的顺序?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 #include <iostream> #include <stdlib.h> #include <time.h> struct Node { Node (int data = 0 ) :data_ (data), next_ (nullptr ) {} int data_; Node* next_; }; void Joseph (Node* head,int k,int m) Node* p = head; Node* q = head; while (q->next_ != head) { q = q->next_; } for (int i = 1 ;i < k;i++) { q = p; p = p->next_; } for (;;) { for (int i = 1 ;i < m;i++) { q = p; p = p->next_; } std::cout << p->data_ << " " ; if (p == q) { delete p; break ; } q->next_ = p->next_; delete p; p = q->next_; } } int main () Node* head = new Node (1 ); Node* n2 = new Node (2 ); Node* n3 = new Node (3 ); Node* n4 = new Node (4 ); Node* n5 = new Node (5 ); Node* n6 = new Node (6 ); Node* n7 = new Node (7 ); Node* n8 = new Node (8 ); head->next_ = n2; n2->next_ = n3; n3->next_ = n4; n4->next_ = n5; n5->next_ = n6; n6->next_ = n7; n7->next_ = n8; n8->next_ = head; Joseph (head, 1 , 3 ); }
双向链表 特点:
每一个节点除了数据域,还有next指针域指向下一个节点,pre指针域指向前一个节点
头节点的pre是NULL,末尾节点的next是NULL。
接口实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 #include <iostream> struct Node { Node (int data = 0 ) : data_ (data) , next_ (nullptr ) , pre_ (nullptr ) {} int data_; Node* next_; Node* pre_; }; class DoubleLink { public : DoubleLink () { head_ = new Node (); } ~DoubleLink () { Node* p = head_; while (p != nullptr ) { Node* q = p->next_; delete p; p = q; } } public : void InsertHead (int val) { Node* node = new Node (val); node->next_ = head_->next_; node->pre_ = head_; if (head_->next_ != nullptr ) { head_->next_->pre_ = node; } head_->next_ = node; } void InsertTail (int val) { Node* p = head_; while (p->next_ != nullptr ) { p = p->next_; } Node* node = new Node (val); p->next_ = node; node->pre_ = p; } void Remove (int val) { Node* p = head_->next_; while (p != nullptr ) { if (p->data_ == val) { p->pre_->next_ = p->next_; if (p->next_ != nullptr ) { p->next_->pre_ = p->pre_; } Node* next = p->next_; delete p; p = next; } else { p = p->next_; } } } bool Find (int val) { Node* p = head_->next_; while (p != nullptr ) { if (p->data_ == val) { return true ; } p = p->next_; } return false ; } void Show () { Node* p = head_->next_; while (p != nullptr ) { std::cout << p->data_ << " " ; p = p->next_; } std::cout << std::endl; } private : Node* head_; }; int main () DoubleLink dLink; dLink.InsertTail (20 ); dLink.InsertTail (12 ); dLink.InsertTail (78 ); dLink.InsertTail (32 ); dLink.InsertTail (7 ); dLink.InsertTail (90 ); dLink.Show (); dLink.InsertHead (100 ); dLink.Show (); dLink.Remove (78 ); dLink.Show (); }
双向循环链表 特点:
每一个节点除了数据域,还有next指针域指向下一个节点,pre指针域指向前一个节点。
头节点的pre指向末尾节点,末尾节点的next指向头节点。
C++ list容器底层就是双向循环链表
接口实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 #include <iostream> struct Node { Node (int data = 0 ) : data_ (data) , next_ (nullptr ) , pre_ (nullptr ) {} int data_; Node* next_; Node* pre_; }; class DoubleCircleLink { public : DoubleCircleLink () { head_ = new Node (); head_->next_ = head_; head_->pre_ = head_; } ~DoubleCircleLink () { Node* p = head_->next_; while (p != head_) { Node* q = p->next_; delete p; p = q; } delete head_; head_ = nullptr ; } public : void InsertHead (int val) { Node* node = new Node (val); node->next_ = head_->next_; node->pre_ = head_; head_->next_->pre_ = node; head_->next_ = node; } void InsertTail (int val) { Node* p = head_->pre_; Node* node = new Node (val); node->next_ = head_; node->pre_ = p; head_->pre_ = node; p->next_ = node; } void Remove (int val) { Node* p = head_->next_; while (p != head_) { if (p->data_ == val) { p->pre_->next_ = p->next_; p->next_->pre_ = p->pre_; Node* next = p->next_; delete p; p = next; } else { p = p->next_; } } } bool Find (int val) { Node* p = head_->next_; while (p != head_) { if (p->data_ == val) { return true ; } p = p->next_; } return false ; } void Show () { Node* p = head_->next_; while (p != head_) { std::cout << p->data_ << " " ; p = p->next_; } std::cout << std::endl; } private : Node* head_; }; int main () DoubleCircleLink dLink; dLink.InsertTail (20 ); dLink.InsertTail (12 ); dLink.InsertTail (78 ); dLink.InsertTail (32 ); dLink.InsertTail (7 ); dLink.InsertTail (90 ); dLink.Show (); dLink.InsertHead (100 ); dLink.Show (); dLink.Remove (78 ); dLink.Show (); }
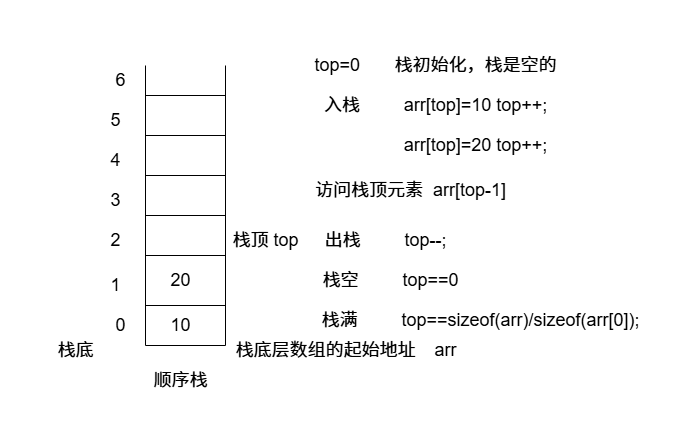
栈 特点: 先进后出,后进先出
顺序栈 依赖数组实现
接口实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 #include <iostream> class SeqStack { public : SeqStack (int size = 10 ) :mtop (0 ) ,mcap (size) { mpStack = new int [mcap]; } ~SeqStack () { delete [] mpStack; mpStack = nullptr ; } public : void push (int val) { if (mtop == mcap) { expand (2 * mcap); } mpStack[mtop++] = val; } void pop () { if (mtop == 0 ) { throw "stack is empty!" ; } mtop--; } int top () const { if (mtop == 0 ) { throw "stack is empty!" ; } return mpStack[mtop - 1 ]; } bool empty () const { return mtop == 0 ; } int size () const { return mtop; } private : void expand (int size) { int * p = new int [size]; memcpy (p, mpStack, mtop*sizeof (int )); delete [] mpStack; mpStack = p; mcap = size; } private : int * mpStack; int mtop; int mcap; }; int main () int arr[] = { 12 ,4 ,56 ,7 ,89 ,31 ,53 ,75 }; SeqStack s; for (int v : arr) { s.push (v); } while (!s.empty ()) { std::cout << s.top () << " " ; s.pop (); } std::cout<<std::endl; }
链式栈 依赖链表实现
接口实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 #include <iostream> class LinkStack { public : LinkStack ():size_ (0 ) { head_ = new Node (); } ~LinkStack () { Node* p = head_->next_; while (p != nullptr ) { head_->next_ = p->next_; delete p; p = head_->next_; } delete head_; head_ = nullptr ; } public : void push (int val) { Node* node = new Node (val); node->next_ = head_->next_; head_->next_ = node; size_++; } void pop () { if (head_->next_ == nullptr ) { throw "Stack is empty!" ; } Node* p = head_->next_; head_->next_ = p->next_; delete p; size_--; } int top () const { if (head_->next_ == nullptr ) { throw "Stack is empty!" ; } return head_->next_->data_; } bool empty () const { return head_->next_ == nullptr ; } int size () const { return size_; } private : struct Node { Node (int data=0 ) :data_ (data) , next_ (nullptr ) {} int data_; Node* next_; }; int size_; Node* head_; }; int main () int arr[] = { 12 ,4 ,56 ,7 ,89 ,31 ,53 ,75 }; LinkStack s; for (int v : arr) { s.push (v); } while (!s.empty ()) { std::cout << s.top () << " " ; s.pop (); } std::cout << std::endl; }
栈的应用 1.有效的括号(leetcode 20)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution {public : bool isValid (string s) std::stack<char > cs; for (char ch:s) { if (ch=='(' ||ch=='[' ||ch=='{' ) { cs.push (ch); }else { if (cs.empty ()) { return false ; } char cmp=cs.top (); cs.pop (); if (ch==')' &&cmp!='(' || ch==']' &&cmp!='[' ||ch=='}' &&cmp!='{' ) { return false ; } } } if (!cs.empty ()) return false ; return true ; } };
2.逆波兰表达式(后缀表达式)求值(leetcode 150)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 class Solution {public : int calc (int left,int right,char sign) { switch (sign) { case '+' : return left+right; case '-' : return left-right; case '*' : return left*right; case '/' : return left/right; } throw "" ; } int evalRPN (vector<string>& tokens) std::stack<int > intStack; for (string &str:tokens) { if (str.size ()==1 && (str[0 ]=='+' ||str[0 ]=='-' ||str[0 ]=='*' ||str[0 ]=='/' )) { int right=intStack.top (); intStack.pop (); int left=intStack.top (); intStack.pop (); intStack.push (calc (left,right,str[0 ])); }else { intStack.push (stoi (str)); } } return intStack.top (); } };
3.中缀转后缀表达式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 #include <iostream> #include <string> #include <stack> bool Priority (char ch, char topch) if ((ch == '*' || ch == '/' ) && (topch == '+' || topch == '-' )) { return true ; } if (topch == '(' &&ch!=')' ) { return true ; } return false ; } std::string MiddleToEndExpr (std::string expr) { std::string result; std::stack < char > s; for (char ch : expr) { if (ch >= '0' && ch <= '9' ) { result += ch; } else { for (;;) { if (s.empty () || ch == '(' ) { s.push (ch); break ; } char topch = s.top (); if (Priority (ch, topch)) { s.push (ch); break ; } else { s.pop (); if (topch == '(' ) break ; result += topch; } } } } while (!s.empty ()) { result += s.top (); s.pop (); } return result; } int main () std::cout << MiddleToEndExpr ("(1+2)*(3+4)" ) << std::endl; std::cout << MiddleToEndExpr ("2+(4+6)/2+6/3" ) << std::endl; std::cout << MiddleToEndExpr ("2+6/(4-2)+(4+6)/2" ) << std::endl; }
队列 特点:先进先出,后进后出
环形队列
依赖数组实现,但必须实现环形
接口实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 #include <iostream> class Queue { public : Queue (int size = 10 ) :cap_ (size) , front_ (0 ) , rear_ (0 ) , size_ (0 ) { pQue_ = new int [cap_]; } ~Queue () { delete [] pQue_; pQue_ = nullptr ; } public : void push (int val) { if ((rear_ + 1 ) % cap_ == front_) { expand (2 * cap_); } pQue_[rear_] = val; size_++; rear_ = (rear_ + 1 ) % cap_; } void pop () { if (front_ == rear_) throw "queue is empty!" ; front_ = (front_ + 1 ) % cap_; size_--; } int front () const { if (front_ == rear_) throw "queue is empty!" ; return pQue_[front_]; } int back () const { if (front_ == rear_) throw "queue is empty!" ; return pQue_[(rear_ - 1 + cap_) % cap_]; } bool empty () const { return front_ == rear_; } int size () const { return size_; } private : void expand (int size) { int * p = new int [size]; int i = 0 ; int j = front_; for (;j!=rear_;i++,j=(j+1 )%cap_) { p[i] = pQue_[j]; } cap_ = size; delete [] pQue_; pQue_ = p; front_ = 0 ; rear_ = i; } private : int * pQue_; int cap_; int front_; int rear_; int size_; }; int main () int arr[] = { 12 ,4 ,56 ,7 ,89 ,31 ,53 ,75 }; Queue que; for (int v : arr) { que.push (v); } std::cout << que.front () << std::endl; std::cout << que.back () << std::endl; que.push (100 ); que.push (200 ); que.push (300 ); std::cout << que.front () << std::endl; std::cout << que.back () << std::endl; while (!que.empty ()) { std::cout << que.front () << " " << que.back () << std::endl;; que.pop (); } }
链式队列 依赖链表实现,通过双向循环链表实现
接口实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 #include <iostream> class LinkQueue { public : LinkQueue () { head_ = new Node (); head_->next_ = head_; head_->pre_ = head_; } ~LinkQueue () { Node* p = head_->next_; while (p != head_) { head_->next_ = p->next_; p->next_->pre_ = head_; delete p; p = head_->next_; } delete head_; head_ = nullptr ; } public : void push (int val) { Node* node = new Node (val); node->next_ = head_; node->pre_ = head_->pre_; head_->pre_->next_ = node; head_->pre_ = node; } void pop () { if (head_->next_ == head_) throw "队列为空" ; Node* p = head_->next_; head_->next_ = p->next_; p->next_->pre_ = head_; delete p; } int front () const { if (head_->next_ == head_) throw "队列为空" ; return head_->next_->data_; } int back () const { if (head_->next_ == head_) throw "队列为空" ; return head_->pre_->data_; } bool empty () { return head_->next_ == head_; } private : struct Node { Node (int data=0 ) :data_ (data) ,next_ (nullptr ) ,pre_ (nullptr ) {} int data_; Node* next_; Node* pre_; }; Node* head_; }; int main () int arr[] = { 12 ,4 ,56 ,7 ,89 ,31 ,53 ,75 }; LinkQueue que; for (int v : arr) { que.push (v); } std::cout << que.front () << std::endl; std::cout << que.back () << std::endl; que.push (100 ); que.push (200 ); que.push (300 ); std::cout << que.front () << std::endl; std::cout << que.back () << std::endl; while (!que.empty ()) { std::cout << que.front () << " " << que.back () << std::endl;; que.pop (); } }
队列应用 1.用栈实现队列(leetcode 232)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 class MyQueue {public : MyQueue () { } void push (int x) s1. push (x); } int pop () if (s1. empty ()&&s2. empty ()) { throw "队列为空" ; }else if (s2. empty ()) { while (!s1. empty ()) { int x=s1. top (); s2. push (x); s1. pop (); } } int x=s2. top (); s2. pop (); return x; } int peek () if (s1. empty ()&&s2. empty ()) { throw "队列为空" ; }else if (s2. empty ()) { while (!s1. empty ()) { int x=s1. top (); s2. push (x); s1. pop (); } } return s2. top (); } bool empty () return s1. empty ()&&s2. empty (); } private : std::stack<int > s1,s2; };
2.用队列实现栈(leetcode 225)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 class MyStack {public : MyStack () { } void push (int x) que.push (x); if (!que.empty ()) { for (int i=1 ;i<que.size ();i++) { int val=que.front (); que.pop (); que.push (val); } } } int pop () if (que.empty ()) { throw "栈为空" ; } int val=que.front (); que.pop (); return val; } int top () if (que.empty ()) { throw "栈为空" ; } return que.front (); } bool empty () return que.empty (); } private : std::queue<int > que; };
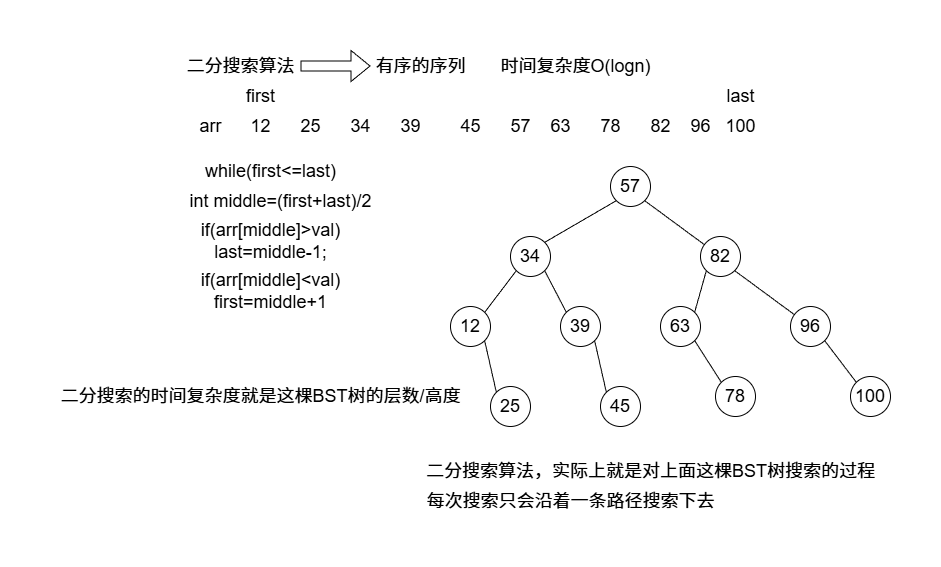
搜索 二分搜索 代码实现和复杂度分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <iostream> int BinarySearch (int arr[], int size, int val) int first = 0 ; int last = size - 1 ; while (first <= last) { int mid = (first + last) / 2 ; if (arr[mid] == val) { return mid; } else if (arr[mid] > val) { last = mid - 1 ; } else { first = mid + 1 ; } } return -1 ; } int main () int arr[] = { 12 ,25 ,34 ,39 ,45 ,57 ,63 ,78 ,82 ,96 ,100 }; int size = sizeof (arr) / sizeof (arr[0 ]); std::cout << BinarySearch (arr, size, 39 ) << std::endl; std::cout << BinarySearch (arr, size, 45 ) << std::endl; std::cout << BinarySearch (arr, size, 12 ) << std::endl; std::cout << BinarySearch (arr, size, 64 ) << std::endl; }
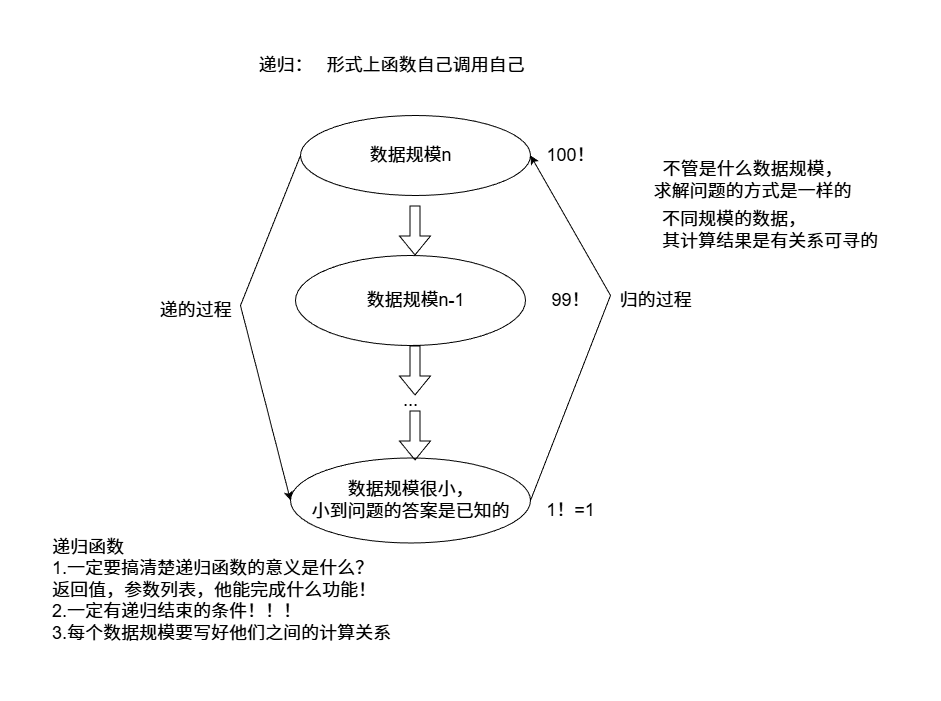
递归实现
递归代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 int BinarySearch1 (int arr[], int i, int j, int val) if (i > j) { return -1 ; } int mid = (i + j) / 2 ; if (arr[mid] == val) { return mid; } else if (arr[mid] > val) { BinarySearch1 (arr, i, mid - 1 , val); } else { BinarySearch1 (arr, mid + 1 , j, val); } } int BinarySearch (int arr[], int size, int val) return BinarySearch1 (arr, 0 , size-1 , val); } int main () int arr[] = { 12 ,25 ,34 ,39 ,45 ,57 ,63 ,78 ,82 ,96 ,100 }; int size = sizeof (arr) / sizeof (arr[0 ]); std::cout << BinarySearch (arr, size, 39 ) << std::endl; std::cout << BinarySearch (arr, size, 45 ) << std::endl; std::cout << BinarySearch (arr, size, 12 ) << std::endl; std::cout << BinarySearch (arr, size, 64 ) << std::endl; }
排序算法 冒泡排序
特点:相邻元素两两比较,把值大的元素往下交换。
缺点:数据交换次数太多了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 #include <iostream> #include <stdlib.h> #include <time.h> void BubbleSort (int arr[], int size) for (int i = 0 ;i < size - 1 ;i++) { bool flag = false ; for (int j = 0 ;j < size - 1 - i;j++) { if (arr[j] > arr[j + 1 ]) { int tmp = arr[j]; arr[j] = arr[j + 1 ]; arr[j + 1 ] = tmp; flag = true ; } } if (!flag) return ; } } int main () int arr[10 ]; srand (time (NULL )); for (int i = 0 ;i < 10 ;i++) { arr[i] = rand () % 100 + 1 ; } for (int v : arr) { std::cout << v << " " ; } std::cout << std::endl; BubbleSort (arr, 10 ); for (int v : arr) { std::cout << v << " " ; } std::cout << std::endl; }
选择排序 特点:每次在剩下的元素中选择值最小的元素,和当前元素进行交换。
缺点:相比于冒泡排序,交换的次数少了,但是比较的次数依然很多。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 #include <iostream> #include <stdlib.h> #include <time.h> void ChoiceSort (int arr[], int size) for (int i = 0 ;i < size - 1 ;i++) { int min = arr[i]; int k = i; for (int j = i+1 ;j < size;j++) { if (min > arr[j]) { min = arr[j]; k = j; } } if (i != k) { int tmp = arr[i]; arr[i] = arr[k]; arr[k] = tmp; } } } int main () int arr[10 ]; srand (time (NULL )); for (int i = 0 ;i < 10 ;i++) { arr[i] = rand () % 100 + 1 ; } for (int v : arr) { std::cout << v << " " ; } std::cout << std::endl; ChoiceSort (arr, 10 ); for (int v : arr) { std::cout << v << " " ; } std::cout << std::endl; }
插入排序 特点:从第二个元素开始,把前面的元素序列当作已经有序的,然后找合适的位置插入。
优点:插入排序是普通排序中效率最高的排序算法,而且在数据越趋于有序的情况下,插入排序的效率是最高的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #include <iostream> #include <stdlib.h> #include <time.h> void InsertSort (int arr[], int size) for (int i = 1 ;i < size;i++) { int val = arr[i]; int j = i - 1 ; for (;j >= 0 ;j--) { if (arr[j] <= val) { break ; } arr[j + 1 ] = arr[j]; } arr[j + 1 ] = val; } } int main () int arr[10 ]; srand (time (NULL )); for (int i = 0 ;i < 10 ;i++) { arr[i] = rand () % 100 + 1 ; } for (int v : arr) { std::cout << v << " " ; } std::cout << std::endl; InsertSort (arr, 10 ); for (int v : arr) { std::cout << v << " " ; } std::cout << std::endl; }
希尔排序 特点:可以看作是多路的插入排序,分组的数据越趋于有序,整体的数据也越趋于有序,插入排序效率完美体现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include <iostream> #include <stdlib.h> #include <time.h> void ShellSort (int arr[], int size) for (int gap = size / 2 ;gap != 0 ;gap = gap / 2 ) { for (int i = gap;i < size;i++) { int val = arr[i]; int j = i - gap; for (;j >= 0 ;j-=gap) { if (arr[j] <= val) { break ; } arr[j + gap] = arr[j]; } arr[j + gap] = val; } } } int main () int arr[10 ]; srand (time (NULL )); for (int i = 0 ;i < 10 ;i++) { arr[i] = rand () % 100 + 1 ; } for (int v : arr) { std::cout << v << " " ; } std::cout << std::endl; ShellSort (arr, 10 ); for (int v : arr) { std::cout << v << " " ; } std::cout << std::endl; }
四种排序排序性能对比:
排序算法
100000组(单位:ms)
冒泡排序(效率最低)
19.32s
选择排序(效率次之)
4.066s
插入排序(效率最高)
3.475s
希尔排序(效率更高)
0.019s
排序算法
平均时间复杂度
最好时间复杂度
最坏时间复杂度
空间复杂度
稳定性
冒泡排序
O(n^2)
O(n)
O(n^2)
O(1)
稳定
选择排序
O(n^2)
O(n^2)
O(n^2)
O(1)
不稳定
插入排序
O(n^2)
O(n)
O(n^2)
O(1)
稳定
希尔排序
依赖不同的增量序列设置O(n^1.3)
O(n)
O(n^2)
O(1)
不稳定
插入排序的效率最好,尤其在数据已经趋于有序的情况下,采用插入排序效率最高 。
一般中等数据量的排序都用希尔排序,选择合适的增量序列,效率就已经不错了,如果数据量比较大,可以选择高级的排序算法,如快速排序。
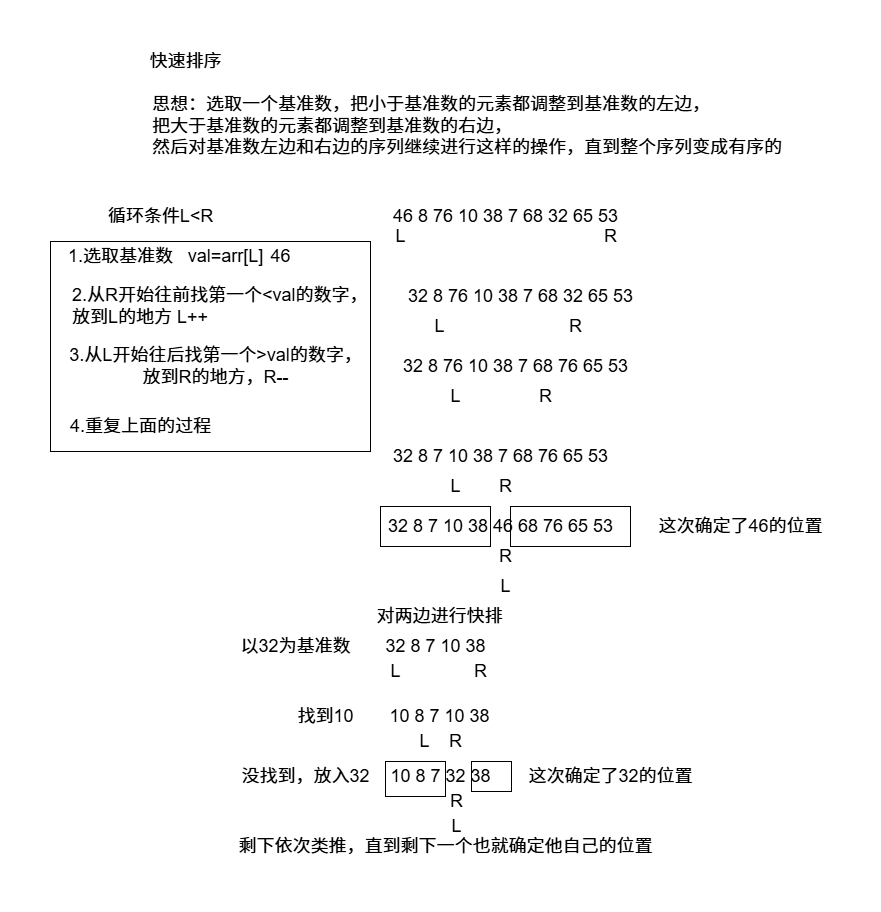
快速排序 冒泡排序的升级算法。
每次选择基准数,把小于基准数的放到基准数的左边,把大于基准数的放到基准数的右边,采用“分治思想”处理剩余的序列元素,直到整个序列变为有序序列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 #include <iostream> #include <stdlib.h> #include <time.h> int Partation (int arr[], int l, int r) int val = arr[l]; while (l < r) { while (l<r && arr[r] > val) { r--; } if (l < r) { arr[l] = arr[r]; l++; } while (l<r && arr[l]<val) { l++; } if (l < r) { arr[r] = arr[l]; r--; } } arr[l] = val; return l; } void QuickSort (int arr[], int begin, int end) if (begin >= end) { return ; } int pos = Partation (arr, begin, end); QuickSort (arr, begin, pos - 1 ); QuickSort (arr, pos + 1 , end); } void QuickSort (int arr[], int size) return QuickSort (arr, 0 , size - 1 ); } int main () int arr[10 ]; srand (time (NULL )); for (int i = 0 ;i < 10 ;i++) { arr[i] = rand () % 100 + 1 ; } for (int v : arr) { std::cout << v << " " ; } std::cout << std::endl; QuickSort (arr, 10 ); for (int v : arr) { std::cout << v << " " ; } std::cout << std::endl; }
算法效率提升:
对于小段趋于有序的序列采用插入排序。(设定序列小到一定数量使用插入排序)
三数取中法。取序列中间的数arr[(l+r)/2],旨在挑选合适的基准数,防止快排退化成冒泡排序
随机数法
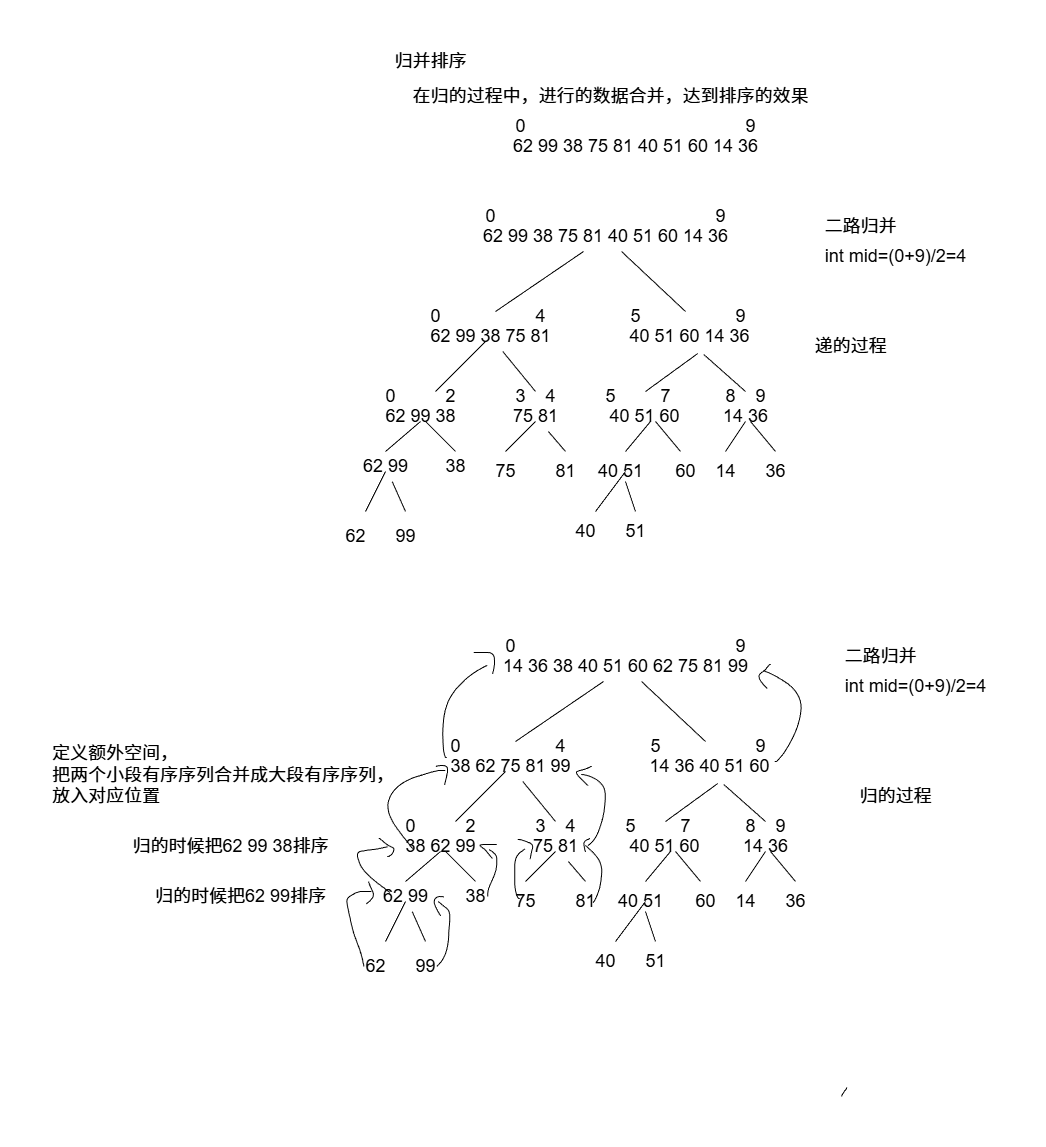
归并排序 也采用“分治思想”,先进行序列划分,再进行元素的有序合并。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 #include <iostream> #include <stdlib.h> #include <time.h> void Merge (int arr[], int l, int m, int r, int * p) int idx = 0 ; int i = l; int j = m + 1 ; while (i <= m && j <= r) { if (arr[i] <= arr[j]) { p[idx++] = arr[i++]; } else { p[idx++] = arr[j++]; } } while (i <= m) { p[idx++] = arr[i++]; } while (j <= r) { p[idx++] = arr[j++]; } for (i = l, j = 0 ;i <= r;i++, j++) { arr[i] = p[j]; } p = nullptr ; } void MergeSort (int arr[], int begin, int end, int * p) if (begin >= end) return ; int mid = (begin + end) / 2 ; MergeSort (arr, begin, mid, p); MergeSort (arr, mid + 1 , end, p); Merge (arr, begin, mid, end, p); } void MergeSort (int arr[], int size) int * p = new int [size]; MergeSort (arr, 0 , size - 1 , p); delete []p; } int main () int arr[10 ]; srand (time (NULL )); for (int i = 0 ;i < 10 ;i++) { arr[i] = rand () % 100 + 1 ; } for (int v : arr) { std::cout << v << " " ; } std::cout << std::endl; MergeSort (arr, 10 ); for (int v : arr) { std::cout << v << " " ; } std::cout << std::endl; }
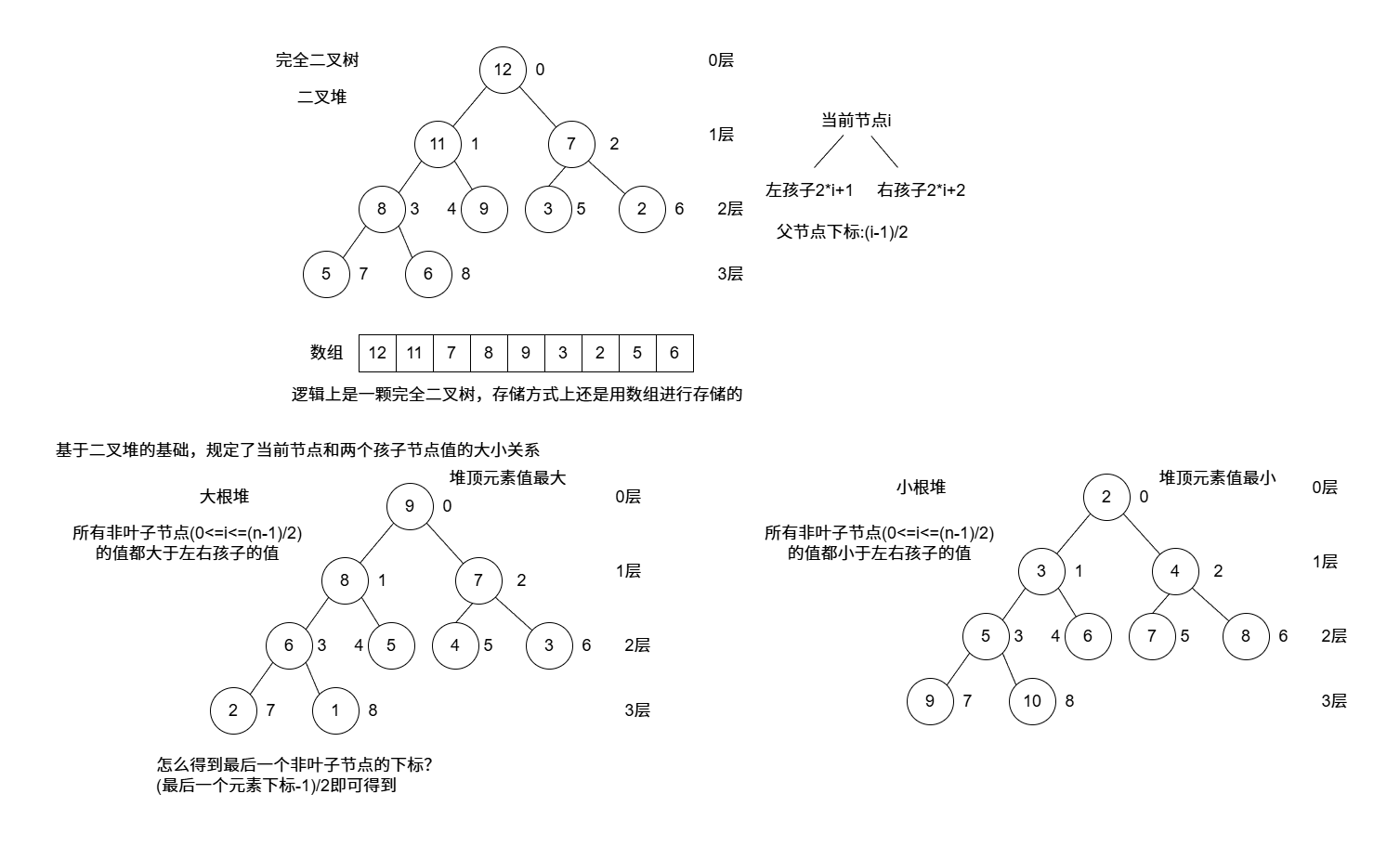
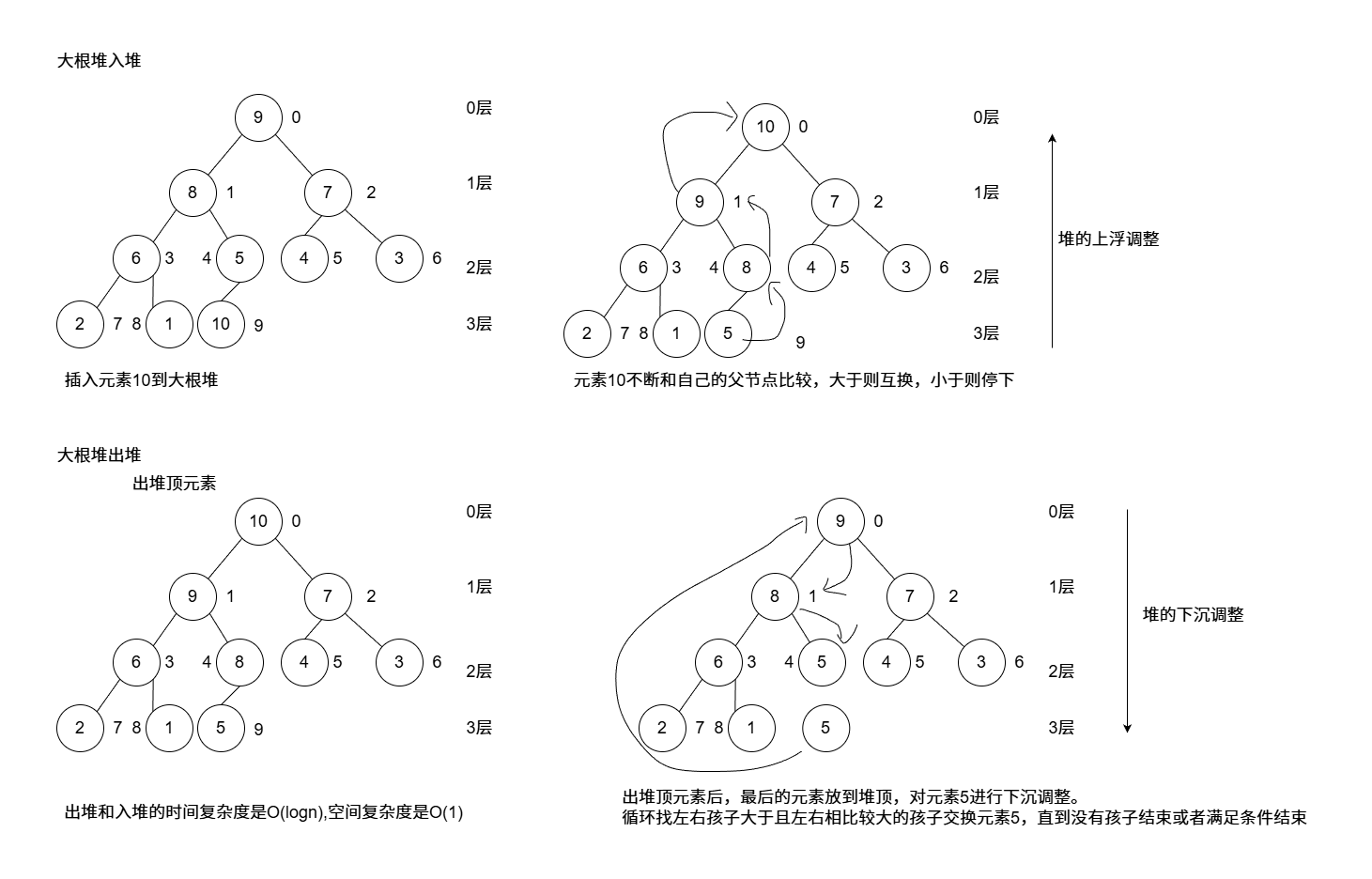
堆排序 二叉堆
就是一颗完全二叉树 ,分为两种典型的堆,分别是大根堆 和小根堆
满足0<=i<=(n-1)/2,n代表最后一个元素的下标。
如果arr[i]<=arr[2i+1]&&arr[i]<=arr[2 i+1+2],就是小根堆
如果arr[i]>=arr[2i+1]&&arr[i]>=arr[2 i+1+2],就是大根堆
基于堆的优先级队列代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 #include <iostream> #include <functional> #include <stdlib.h> #include <time.h> class PriorityQueue { public : using Comp = std::function<bool (int , int )>; PriorityQueue (int cap=20 , Comp comp = std::greater <int >()) :size_ (0 ) , cap_ (cap) , comp_ (comp) { que_ = new int [cap_]; } PriorityQueue (Comp comp) :size_ (0 ) , cap_ (20 ) , comp_ (comp) { que_ = new int [cap_]; } ~PriorityQueue () { delete [] que_; que_ = nullptr ; } public : void push (int val) { if (size_ == cap_) { int * p = new int [2 * cap_]; memcpy (p, que_, cap_ * sizeof (int )); delete [] que_; que_ = p; cap_ *= 2 ; } if (size_ == 0 ) { que_[size_] = val; } else { shiftUp (size_,val); } size_++; } void pop () { if (size_ == 0 ) { throw "container is empty!" ; } size_--; if (size_ > 0 ) { shiftDown (0 ,que_[size_]); } } bool empty () const { return size_ == 0 ; } int top () const { if (size_ == 0 ) { throw "container is empty!" ; } return que_[0 ]; } int size () const { return size_; } private : void shiftUp (int i, int val) { while (i > 0 ) { int father = (i - 1 ) / 2 ; if (comp_ (val, que_[father])) { que_[i] = que_[father]; i = father; } else { break ; } } que_[i] = val; } void shiftDown (int i, int val) { while (2 * i + 1 < size_) { int child = 2 * i + 1 ; if (child + 1 < size_ && comp_ (que_[child + 1 ], que_[child])) { child = child + 1 ; } if (comp_ (que_[child], val)) { que_[i] = que_[child]; i = child; } else { break ; } } que_[i] = val; } private : int * que_; int size_; int cap_; Comp comp_; }; int main () PriorityQueue que ([](int a, int b) {return a < b;}) srand (time (NULL )); for (int i = 0 ;i < 10 ;i++) { que.push (rand () % 100 ); } while (!que.empty ()) { std::cout << que.top () << " " ; que.pop (); } std::cout << std::endl; }
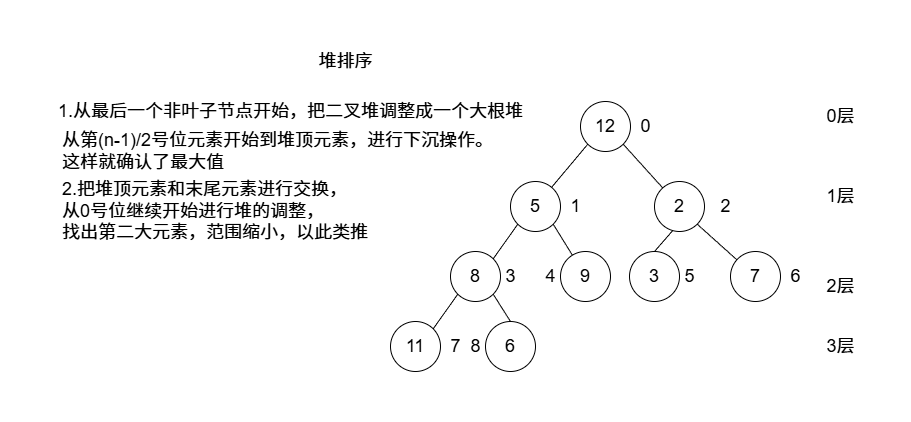
堆排序代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 #include <iostream> #include <stdlib.h> #include <time.h> void shiftDown (int arr[], int i, int size) int val = arr[i]; while (2 * i + 1 < size) { int child = 2 * i + 1 ; if (child + 1 < size && arr[child + 1 ] > arr[child]) { child = child + 1 ; } if (arr[child] > val) { arr[i] = arr[child]; i = child; } else { break ; } } arr[i] = val; } void HeapSort (int arr[], int size) int n = size - 1 ; for (int i = (n - 1 ) / 2 ;i >= 0 ;i--) { shiftDown (arr, i, size); } for (int i = n;i > 0 ;i--) { int tmp = arr[i]; arr[i] = arr[0 ]; arr[0 ] = tmp; shiftDown (arr, 0 , i); } } int main () int arr[10 ]; srand (time (NULL )); for (int i = 0 ;i < 10 ;i++) { arr[i] = rand () % 100 + 1 ; } for (int v : arr) { std::cout << v << " " ; } std::cout << std::endl; HeapSort (arr, 10 ); for (int v : arr) { std::cout << v << " " ; } std::cout << std::endl; }
排序算法
平均时间复杂度
最好时间复杂度
最坏时间复杂度
空间复杂度
稳定性
堆排序
O(n*logn)
O(n*logn)
O(n*logn)
O(1)
不稳定
快速排序
O(n*logn)
O(n*logn)
O(n^2)
O(logn)->O(n)
不稳定
归并排序
O(n*logn)
O(n*logn)
O(n*logn)
O(n)
稳定
快排&归并&堆排序&希尔性能测试
数据规模
快速排序
归并排序
希尔排序
堆排序
1000万
0.974s
1.605s
3.257s
2.274s
5000万
4.871s
8.471s
18.712s
14.718s
1亿
9.717s
17.266s
41.887s
32.279s
1.不管是快排,或者归并排序,遍历元素的时候都是按照顺序遍历的,对CPU缓存是友好的(CPU缓存命中率高)。但是堆排序,访问元素的时候,是按照父子节点的关系访问的,并不是按照顺序访问的,所以排序过程中,不管是进行元素上浮调整,还是下沉调整,对CPU缓存不友好
2.堆排序的过程中,进行元素下沉调整所作的无效比较过多(因为它本身就小,所以最终下沉到的地方,和末尾位置相差不远,中间做了很多比较,无用功太多)
高级算法的一些问题 1.STL里sort算法用的是什么排序算法?
首先用的是快速排序算法,如果待排序的序列个数<=32变为插入排序,如果递归层数太深转为堆排序。
2.快速排序的时间复杂度不是稳定的nlogn,最坏情况会变成n^2,怎么解决复杂度恶化的问题?
三数取中(选择合理的基准数)
3.快速排序递归实现时,怎么解决递归层次过深的问题?
可以设计一个ideal,当ideal达到一个值后使用堆排。(stl::sort用法)
4.递归过深会引发什么问题?
函数开销变大导致栈内存溢出,程序挂掉。
5.怎么控制递归深度?如果达到递归深度了还没排完序怎么办?
达到递归深度可以使用非递归排序算法。
6.假设你只有100Mb的内存,需要对1Gb的数据进行排序,最合适的算法是归并算法
基数排序
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 #include <iostream> #include <stdlib.h> #include <time.h> #include <string> #include <vector> void RadixSort (int arr[], int size) int maxData = arr[0 ]; for (int i = 1 ;i < size;i++) { if (maxData < abs (arr[i])) { maxData = abs (arr[i]); } } int len = std::to_string (maxData).size (); std::vector<std::vector<int >> vecs; int mod = 10 ; int dev = 1 ; for (int i = 0 ;i < len;i++, mod *= 10 , dev *= 10 ) { vecs.resize (20 ); for (int j = 0 ;j < size;j++) { int index = arr[j] % mod / dev+10 ; vecs[index].push_back (arr[j]); } int idx = 0 ; for (auto vec : vecs) { for (int v : vec) { arr[idx++] = v; } } vecs.clear (); } } int main () int arr[10 ]; srand (time (NULL )); for (int i = 0 ;i < 10 ;i++) { arr[i] = rand () % 100 + 1 ; } for (int v : arr) { std::cout << v << " " ; } std::cout << std::endl; RadixSort (arr, 10 ); for (int v : arr) { std::cout << v << " " ; } std::cout << std::endl; }
排序算法
平均时间复杂度
最好时间复杂度
最坏时间复杂度
空间复杂度
稳定性
基数排序
O(nd)
O(nd)
O(nd)
O(n)
稳定
哈希表 散列表/哈希表定义:
使关键字和其存储位置满足关系:存储位置=f(关键字),这是一种新的存储技术-散列技术。
散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key),在查找时,根据这个确定的对应关系找到给定key的映射f(key),如果待查找集合中存在这个记录,则必定在f(key)的位置上。
我们把这种对应关系f称为散列函数,又称为哈希函数。采用散列技术把记录存储在一块连续的存储空间中,这块连续的存储空间称为散列表或者哈希表
优势:适用于快速的查找,时间复杂度O(1)
缺点:占用内存空间比较大,哈希表的空间效率还是不够高。
散列函数:
设计特点:计算简单,散列地址分布均匀
散列冲突处理:
线性探测哈希表实现
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 #include <iostream> enum State { STATE_UNUSE, STATE_USING, STATE_DEL, }; struct Bucket { Bucket (int key = 0 , State state = STATE_UNUSE) :key_ (key) , state_ (state) {} int key_; State state_; }; class HashTable { public : HashTable (int size=primes_[0 ],double loadFactor=0.75 ) :useBucketNum_ (0 ) , loadFactor_ (loadFactor) , primeIdx_ (0 ) { if (size != primes_[0 ]) { for (;primeIdx_ < PRIME_SIZE;primeIdx_++) { if (primes_[primeIdx_] >= size) break ; } if (primeIdx_ == PRIME_SIZE) { primeIdx_--; } } tableSize_ = primes_[primeIdx_]; table_ = new Bucket[tableSize_]; } ~HashTable () { delete [] table_; table_ = nullptr ; } public : bool insert (int key) { double factor = useBucketNum_*1.0 / tableSize_; std::cout << "factor:" << factor << std::endl; if (factor > loadFactor_) { expand (); } int idx = key % tableSize_; int i = idx; do { if (table_[i].state_ != STATE_USING) { table_[i].state_ = STATE_USING; table_[i].key_ = key; useBucketNum_++; return true ; } i = (i + 1 ) % tableSize_; } while (i != idx); throw "没有正常插入元素" ; } bool erase (int key) { int idx = key % tableSize_; int i = idx; do { if (table_[i].state_ == STATE_USING && table_[i].key_ == key) { table_[i].state_ = STATE_DEL; useBucketNum_--; } i = (i + 1 ) % tableSize_; } while (table_[i].state_!=STATE_UNUSE && i != idx); return true ; } bool find (int key) { int idx = key % tableSize_; int i = idx; do { if (table_[i].state_ == STATE_USING && table_[i].key_ == key) { return true ; } i = (i + 1 ) % tableSize_; } while (table_[i].state_ != STATE_UNUSE && i != idx); return false ; } private : void expand () { primeIdx_++; if (primeIdx_ == PRIME_SIZE) { throw "HashTable is too large! can not expand anymore" ; } Bucket* newTable = new Bucket[primes_[primeIdx_]]; for (int i = 0 ;i < tableSize_;i++) { if (table_[i].state_ == STATE_USING) { int idx = table_[i].key_ % primes_[primeIdx_]; int k = idx; do { if (newTable[k].state_ != STATE_USING) { newTable[k].state_ = STATE_USING; newTable[k].key_ = table_[i].key_; break ; } k = (k + 1 ) % primes_[primeIdx_]; } while (k!=idx); } } delete [] table_; table_ = newTable; tableSize_ = primes_[primeIdx_]; } private : Bucket* table_; int tableSize_; int useBucketNum_; double loadFactor_; static const int PRIME_SIZE = 10 ; static int primes_[PRIME_SIZE]; int primeIdx_; }; int HashTable::primes_[PRIME_SIZE] = { 3 ,7 ,47 ,97 ,251 ,443 ,911 ,1471 ,42773 };int main () HashTable htable; htable.insert (21 ); htable.insert (32 ); htable.insert (14 ); htable.insert (15 ); htable.insert (22 ); std::cout << htable.find (15 ) << std::endl; htable.erase (15 ); std::cout << htable.find (15 ) << std::endl; }
链式哈希表实现
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 #include <iostream> #include <vector> #include <list> #include <algorithm> class HashTable { public : HashTable (int size = primes_[0 ], double loadFactor = 0.75 ) :useBucketNum_ (0 ) , loadFactor_ (loadFactor) , primeIdx_ (0 ) { if (size != primes_[0 ]) { for (;primeIdx_ < PRIME_SIZE;primeIdx_++) { if (primes_[primeIdx_] >= size) { break ; } } if (primeIdx_ == PRIME_SIZE) { primeIdx_--; } } table_.resize (primes_[primeIdx_]); } public : void insert (int key) { double factor = useBucketNum_ * 1.0 / table_.size (); std::cout << "factor:" << factor << std::endl; if (factor > loadFactor_) { expand (); } int idx = key % table_.size (); if (table_[idx].empty ()) { useBucketNum_++; table_[idx].emplace_front (key); } else { auto it = std::find (table_[idx].begin (), table_[idx].end (), key); if (it == table_[idx].end ()) { table_[idx].emplace_front (key); } } } void erase (int key) { int idx = key % table_.size (); auto it = std::find (table_[idx].begin (), table_[idx].end (), key); if (it != table_[idx].end ()) { table_[idx].erase (it); if (table_[idx].empty ()) { useBucketNum_; } } } bool find (int key) { int idx = key % table_.size (); auto it = std::find (table_[idx].begin (), table_[idx].end (), key); return it != table_[idx].end (); } private : void expand () { if (primeIdx_ + 1 == PRIME_SIZE) { throw "hashtable can not expand anymore!" ; } primeIdx_++; useBucketNum_ = 0 ; std::vector<std::list<int >> oldTable; table_.swap (oldTable); table_.resize (primes_[primeIdx_]); for (auto list : oldTable) { for (auto key : list) { int idx = key % table_.size (); if (table_.empty ()) { useBucketNum_++; } table_[idx].emplace_front (key); } } } private : std::vector<std::list<int >> table_; int useBucketNum_; double loadFactor_; static const int PRIME_SIZE = 10 ; static int primes_[PRIME_SIZE]; int primeIdx_; }; int HashTable::primes_[PRIME_SIZE] = { 3 ,7 ,47 ,97 ,251 ,443 ,911 ,1471 ,42773 };int main () HashTable htable; htable.insert (21 ); htable.insert (32 ); htable.insert (14 ); htable.insert (15 ); htable.insert (22 ); htable.insert (67 ); std::cout << htable.find (15 ) << std::endl; htable.erase (15 ); std::cout << htable.find (15 ) << std::endl; }
大数据处理 查重
哈希表
查重或者统计重复的次数。查询的效率高但是占用内存空间较大。
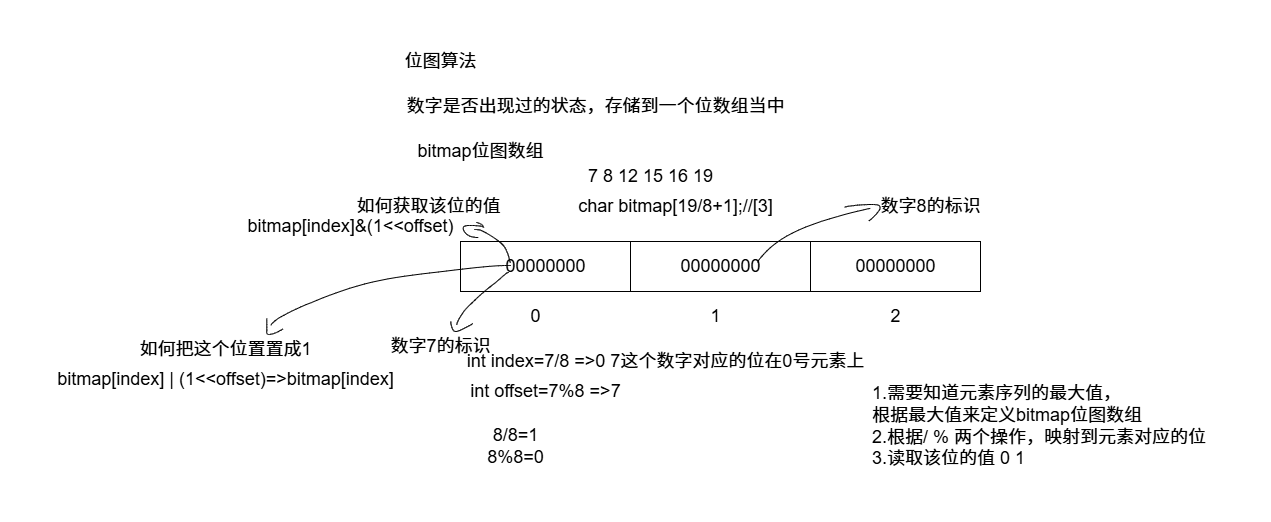
位图
位图法,就是用一个位(0/1)来存储数据的状态,比较适合状态简单,数据量比较大,要求内存使用率低的问题场景。
位图法解决问题,首先需要知道待处理数据中的最大值,然后按照size=(maxNumber/32)+1的大小来开辟一个int类型的数组,当需要在位图查找某个元素是否存在的时候,首先需要计算该数字对应的数组中的比特位,然后读取值,0表示不存在,1表示已存在。
位图法有一个很大的缺点,就是数据没有多少,但是最大值却很大,比如有10个整数,最大值是10亿,那么就得按10亿这个数字计算开辟位图数组的大小,太浪费内存空间。
布隆过滤器
在内存有所限制的情况下,快速判断一个元素是否在一个集合(容器)当中,还可以使用布隆过滤器。在使用哈希表比较占内存的情况下,它是一种更高级的“位图法”解决方案,它避免了简单位图法的缺陷。
Bloom Filter是通过一个位数组+k个哈希函数构成的。
Bloom Filter的空间和时间利用率都很高,但是它有一定的错误率。虽然错误率很低,Bloom Filter判断某个元素不在一个集合中,那该元素肯定不在集合中;Bloom Filter判断某个元素在一个集合中,那该元素有可能在,有可能不在集合当中。
Bloom Filter的查找错误率,当然和位数组的大小,以及哈希函数的个数有关系,具体的错误率计算有相应的公式
Bloom Filter默认只支持add增加和query查询操作,不支持delete删除操作(因为存储的状态位有可能也是其他数据的状态位,删除后导致其他元素查找判断出错)。
Bloom Filter增加元素的过程:把元素的值通过k个哈希函数进行计算,得到k个值,然后把值当作位数组的下标,在位数组中把相应k个值修改为1。
Bloom Filter查询元素的过程:把元素的值通过k个哈希函数进行计算,得到k个值,然后把值当作位数组的下标,看看相应位数组下标标识的值是否全部是1,如果有一个1为0,表示元素不存在(判断不存在绝对正确);如果都为1,表示元素存在(判断存在有错误率)。
很显然,过小的布隆过滤器很快所有的bit位均为1,那么查询任何值都会返回“可能存在”,起不到过滤的目的。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器bit位置为1的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那误报率就会变高。
哈希表应用查重 代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 #include <iostream> #include <vector> #include <unordered_set> #include <unordered_map> #include <stdlib.h> #include <time.h> #include <string> #if 0 int main () std::vector<int > vec; srand (time (NULL )); for (int i = 0 ;i < 10000 ;i++) { vec.push_back (rand () % 10000 ); } std::unordered_set<int > s1; for (auto key : vec) { auto it = s1.f ind(key); if (it == s1. end ()) { s1. insert (key); } else { std::cout << "第一个重复的key:" << key << std::endl; break ; } } std::unordered_map<int , int > m1; for (int key : vec) { auto it = m1.f ind(key); if (it == m1. end ()) { m1. emplace (key, 1 ); } else { it->second += 1 ; } } for (auto pair : m1) { if (pair.second > 1 ) { std::cout << "key:" << pair.first << "出现的次数:" << pair.second << std::endl; } } std::unordered_set<int > s2; for (auto key : vec) { s1. emplace (key); } } #endif int main () std::string src = "jjhfgiyurtytrs" ; std::unordered_map<char , int > m; for (char ch : src) { m[ch]++; } for (char ch : src) { if (m[ch] == 1 ) { std::cout << "第一个没有重复出现过的字符是:" << ch << std::endl; return 0 ; } } std::cout << "所有字符都有重复出现过!" << std::endl; return 0 ; }
位图法应用查重 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #include <iostream> #include <vector> #include <stdlib.h> #include <time.h> #include <memory> int main () std::vector<int > vec{ 12 ,78 ,90 ,12 ,123 ,8 ,9 }; int max = vec[0 ]; for (int i = 1 ;i < vec.size ();i++) { if (vec[i] > max) max = vec[i]; } std::cout << max << std::endl; int * bitmap = new int [max / 32 + 1 ](); std::unique_ptr<int > ptr (bitmap) ; for (auto key : vec) { int index = key / 32 ; int offset = key % 32 ; if (0 == (bitmap[index] & (1 << offset))) { bitmap[index] |= (1 << offset); } else { std::cout << key << "是第一个重复出现的数字" << std::endl; return 0 ; } } }
布隆过滤器应用查重 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 #include <iostream> #include <vector> #include "stringhash.hpp" #include <string> class BloomFilter { public : BloomFilter (int bitSize = 1471 ) :bitSize_ (bitSize) { bitMap_.resize (bitSize_ / 32 + 1 ); } public : void setBit (const char * str) { int idx1 = BKDRHash (str) % bitSize_; int idx2 = RSHash (str) % bitSize_; int idx3 = APHash (str) % bitSize_; int index=0 ; int offset=0 ; index = idx1 / 32 ; offset = idx1 % 32 ; bitMap_[index] |= (1 << offset); index = idx2 / 32 ; offset = idx2 % 32 ; bitMap_[index] |= (1 << offset); index = idx3 / 32 ; offset = idx3 % 32 ; bitMap_[index] |= (1 << offset); } bool getBit (const char * str) { int idx1 = BKDRHash (str) % bitSize_; int idx2 = RSHash (str) % bitSize_; int idx3 = APHash (str) % bitSize_; int index = 0 ; int offset = 0 ; index = idx1 / 32 ; offset = idx1 % 32 ; if (0 == (bitMap_[index] & (1 << offset))) { return false ; } index = idx2 / 32 ; offset = idx2 % 32 ; if (0 == (bitMap_[index] & (1 << offset))) { return false ; } index = idx3 / 32 ; offset = idx3 % 32 ; if (0 == (bitMap_[index] & (1 << offset))) { return false ; } return true ; } private : int bitSize_; std::vector<int > bitMap_; }; class BlackList { public : void add (std::string url) { blockList_.setBit (url.c_str ()); } bool query (std::string url) { return blockList_.getBit (url.c_str ()); } private : BloomFilter blockList_; }; int main () BlackList list; list.add ("http://www.baidu.com" ); list.add ("http://www.360buy.com" ); list.add ("http://www.tmall.com" ); list.add ("http://www.tencent.com" ); std::string url = "http://www.tmall.com" ; std::cout << list.query (url) << std::endl; std::string url1 = "http://www.mall.com" ; std::cout << list.query (url1) << std::endl; }
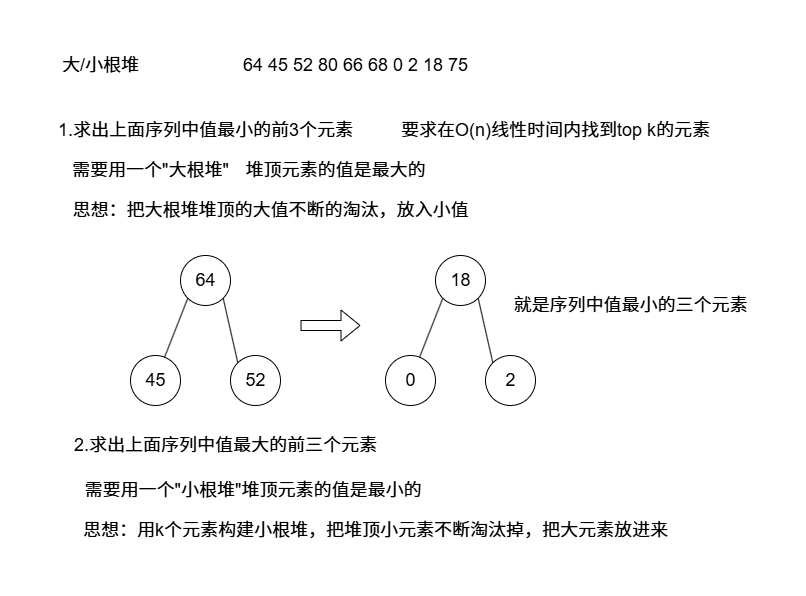
求top k问题
大/小根堆求解top k
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 #include <iostream> #include <time.h> #include <stdlib.h> #include <vector> #include <queue> #include <functional> #include <unordered_map> #if 0 int main () std::vector<int > vec; srand (time (NULL )); for (int i = 0 ;i < 1000 ;i++) { vec.push_back (rand () % 10000 ); } #if 0 std::priority_queue<int > maxheap; int k = 5 ; for (int i = 0 ;i < 5 ;i++) { maxheap.push (vec[i]); } for (int i = 5 ;i < vec.size ();i++) { if (maxheap.top () > vec[i]) { maxheap.pop (); maxheap.push (vec[i]); } } while (!maxheap.empty ()) { std::cout << maxheap.top () << " " ; maxheap.pop (); } #endif std::priority_queue<int ,std::vector<int >,std::greater<int >> minheap; int k = 5 ; for (int i = 0 ;i < 5 ;i++) { minheap.push (vec[i]); } for (int i = 5 ;i < vec.size ();i++) { if (minheap.top () < vec[i]) { minheap.pop (); minheap.push (vec[i]); } } while (!minheap.empty ()) { std::cout << minheap.top () << " " ; minheap.pop (); } } #endif int main () std::vector<int > vec; srand (time (NULL )); for (int i = 0 ;i < 10000 ;i++) { vec.push_back (rand () % 1000 ); } #if 0 std::unordered_map<int , int > map; int k = 3 ; for (auto key : vec) { map[key]++; } using Type = std::pair<int , int >; using Comp = std::function<bool (Type&, Type&)>; std::priority_queue<Type, std::vector<Type>, Comp> maxheap ([](Type &a,Type &b)->bool { return a.second < b.second; }); auto it = map.begin (); for (int i = 0 ;i < k;i++,++it) { maxheap.push (*it); } for (;it != map.end ();++it) { if (maxheap.top ().second > it->second) { maxheap.pop (); maxheap.push (*it); } } while (!maxheap.empty ()) { std::cout << "key:" << maxheap.top ().first << " cnt:" << maxheap.top ().second << std::endl; maxheap.pop (); } #endif std::unordered_map<int , int > map; int k = 3 ; for (auto key : vec) { map[key]++; } using Type = std::pair<int , int >; using Comp = std::function<bool (Type&, Type&)>; std::priority_queue<Type, std::vector<Type>, Comp> minheap ([](Type& a, Type& b)->bool { return a.second > b.second; }); auto it = map.begin (); for (int i = 0 ;i < k;i++, ++it) { minheap.push (*it); } for (;it != map.end ();++it) { if (minheap.top ().second < it->second) { minheap.pop (); minheap.push (*it); } } while (!minheap.empty ()) { std::cout << "key:" << minheap.top ().first << " cnt:" << minheap.top ().second << std::endl; minheap.pop (); } }
快排分割求解top k
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 #include <iostream> int Partation (int arr[], int begin, int end) int val = arr[begin]; int i = begin; int j = end; while (i < j) { while (i<j && arr[j] > val) j--; if (i < j) { arr[i] = arr[j]; i++; } while (i < j && arr[i] < val) i++; if (i < j) { arr[j] = arr[i]; j--; } } arr[i] = val; return i; } void SelectTopK (int arr[], int begin, int end, int k) int pos = Partation (arr, begin, end); if (pos == k - 1 ) { return ; } else if (pos > k - 1 ) { SelectTopK (arr, begin, pos - 1 ,k); } else { SelectTopK (arr, pos + 1 , end, k); } } int main () int arr[] = { 64 ,45 ,52 ,80 ,66 ,68 ,0 ,2 ,18 ,75 }; int size = sizeof (arr) / sizeof (arr[0 ]); int k = 3 ; SelectTopK (arr, 0 , size - 1 , k); for (int i = 0 ;i < k;i++) { std::cout << arr[i] << " " ; } std::cout << std::endl; }